Microservice Pattern: SAGA
Context
You are developing a server-side enterprise application. It must support a variety of different clients including desktop browsers, mobile browsers and native mobile applications. The application might also expose an API for 3rd parties to consume. It might also integrate with other applications via either web services or a message broker. The application handles requests (HTTP requests and messages) by executing business logic; accessing a database; exchanging messages with other systems; and returning a HTML/JSON/XML response. There are logical components corresponding to different functional areas of the application.
Problem
What’s the application’s deployment architecture?
Forces
- There is a team of developers working on the application
- New team members must quickly become productive
- The application must be easy to understand and modify
- You want to practice continuous deployment of the application
- You must run multiple instances of the application on multiple machines in order to satisfy scalability and availability requirements
- You want to take advantage of emerging technologies (frameworks, programming languages, etc)
Solution
Define an architecture that structures the application as a set of loosely coupled, collaborating services. This approach corresponds to the Y-axis of the Scale Cube. Each service is:
- Highly maintainable and testable - enables rapid and frequent development and deployment
- Loosely coupled with other services - enables a team to work independently the majority of time on their service(s) without being impacted by changes to other services and without affecting other services
- Independently deployable - enables a team to deploy their service without having to coordinate with other teams
- Capable of being developed by a small team - essential for high productivity by avoiding the high communication head of large teams
Services communicate using either synchronous protocols such as HTTP/REST or asynchronous protocols such as AMQP. Services can be developed and deployed independently of one another. Each service has its own database in order to be decoupled from other services. Data consistency between services is maintained using the Saga pattern
To learn more about the nature of a service, please read this article.
Examples
Fictitious e-commerce application
Let’s imagine that you are building an e-commerce application that takes orders from customers, verifies inventory and available credit, and ships them. The application consists of several components including the StoreFrontUI, which implements the user interface, along with some backend services for checking credit, maintaining inventory and shipping orders. The application consists of a set of services.
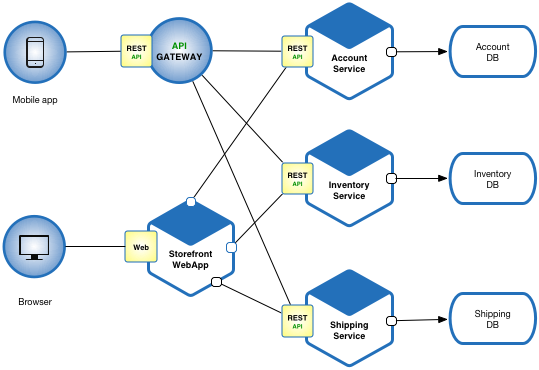
Show me the code
Please see the example applications developed by Chris Richardson. These examples on Github illustrate various aspects of the microservice architecture.
Resulting context
Benefits
This solution has a number of benefits:
- Enables the continuous delivery and deployment of large, complex applications.
- Improved maintainability - each service is relatively small and so is easier to understand and change
- Better testability - services are smaller and faster to test
- Better deployability - services can be deployed independently
- It enables you to organize the development effort around multiple, autonomous teams. Each (so called two pizza) team owns and is responsible for one or more services. Each team can develop, test, deploy and scale their services independently of all of the other teams.
- Each microservice is relatively small:
- Easier for a developer to understand
- The IDE is faster making developers more productive
- The application starts faster, which makes developers more productive, and speeds up deployments
- Improved fault isolation. For example, if there is a memory leak in one service then only that service will be affected. The other services will continue to handle requests. In comparison, one misbehaving component of a monolithic architecture can bring down the entire system.
- Eliminates any long-term commitment to a technology stack. When developing a new service you can pick a new technology stack. Similarly, when making major changes to an existing service you can rewrite it using a new technology stack.
Drawbacks
This solution has a number of drawbacks:
- Developers must deal with the additional complexity of creating a distributed system:
- Developers must implement the inter-service communication mechanism and deal with partial failure
- Implementing requests that span multiple services is more difficult
- Testing the interactions between services is more difficult
- Implementing requests that span multiple services requires careful coordination between the teams
- Developer tools/IDEs are oriented on building monolithic applications and don’t provide explicit support for developing distributed applications.
- Deployment complexity. In production, there is also the operational complexity of deploying and managing a system comprised of many different services.
- Increased memory consumption. The microservice architecture replaces N monolithic application instances with NxM services instances. If each service runs in its own JVM (or equivalent), which is usually necessary to isolate the instances, then there is the overhead of M times as many JVM runtimes. Moreover, if each service runs on its own VM (e.g. EC2 instance), as is the case at Netflix, the overhead is even higher.
Issues
There are many issues that you must address.
When to use the microservice architecture?
One challenge with using this approach is deciding when it makes sense to use it. When developing the first version of an application, you often do not have the problems that this approach solves. Moreover, using an elaborate, distributed architecture will slow down development. This can be a major problem for startups whose biggest challenge is often how to rapidly evolve the business model and accompanying application. Using Y-axis splits might make it much more difficult to iterate rapidly. Later on, however, when the challenge is how to scale and you need to use functional decomposition, the tangled dependencies might make it difficult to decompose your monolithic application into a set of services.
How to decompose the application into services?
Another challenge is deciding how to partition the system into microservices. This is very much an art, but there are a number of strategies that can help:
- Decompose by business capability and define services corresponding to business capabilities.
- Decompose by domain-driven design subdomain.
- Decompose by verb or use case and define services that are responsible for particular actions. e.g. a
Shipping Servicethat’s responsible for shipping complete orders. - Decompose by by nouns or resources by defining a service that is responsible for all operations on entities/resources of a given type. e.g. an
Account Servicethat is responsible for managing user accounts.
Ideally, each service should have only a small set of responsibilities. (Uncle) Bob Martin talks about designing classes using the Single Responsibility Principle (SRP). The SRP defines a responsibility of a class as a reason to change, and states that a class should only have one reason to change. It make sense to apply the SRP to service design as well.
Another analogy that helps with service design is the design of Unix utilities. Unix provides a large number of utilities such as grep, cat and find. Each utility does exactly one thing, often exceptionally well, and is intended to be combined with other utilities using a shell script to perform complex tasks.
How to maintain data consistency?
In order to ensure loose coupling, each service has its own database. Maintaining data consistency between services is a challenge because 2 phase-commit/distributed transactions is not an option for many applications. An application must instead use the Saga pattern. A service publishes an event when its data changes. Other services consume that event and update their data. There are several ways of reliably updating data and publishing events including Event Sourcing and Transaction Log Tailing.
How to implement queries?
Another challenge is implementing queries that need to retrieve data owned by multiple services.
- The API Composition and Command Query Responsibility Segregation (CQRS) patterns.
Pattern: Saga
Context
You have applied the Database per Service pattern. Each service has its own database. Some business transactions, however, span multiple service so you need a mechanism to implement transactions that span services. For example, let’s imagine that you are building an e-commerce store where customers have a credit limit. The application must ensure that a new order will not exceed the customer’s credit limit. Since Orders and Customers are in different databases owned by different services the application cannot simply use a local ACID transaction.
Problem
How to implement transactions that span services?
Forces
- 2PC is not an option
Solution
Implement each business transaction that spans multiple services is a saga. A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
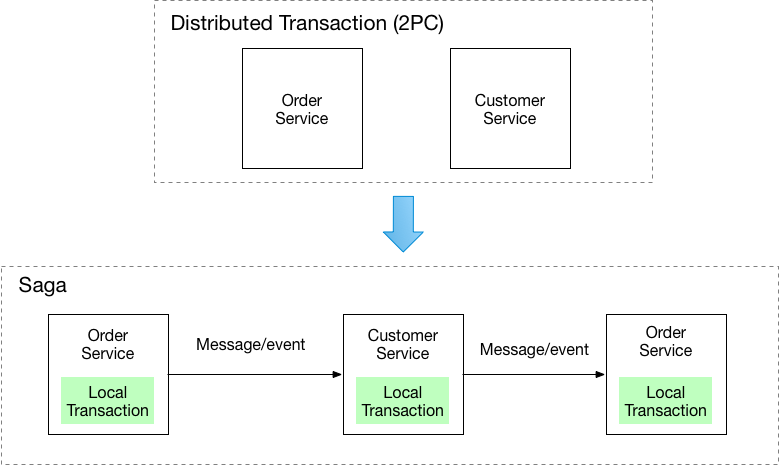
There are two ways of coordination sagas:
- Choreography - each local transaction publishes domain events that trigger local transactions in other services
- Orchestration - an orchestrator (object) tells the participants what local transactions to execute
Example: Choreography-based saga
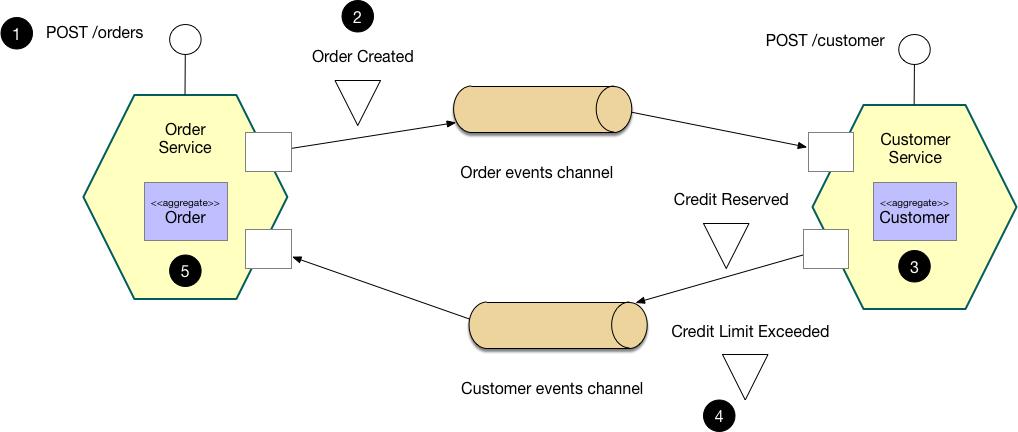
An e-commerce application that uses this approach would create an order using a choreography-based saga that consists of the following steps:
- The
Order Servicereceives thePOST /ordersrequest and creates anOrderin aPENDINGstate - It then emits an
Order Createdevent - The
Customer Service’s event handler attempts to reserve credit - It then emits an event indicating the outcome
- The
OrderService’s event handler either approves or rejects theOrder
Example: Orchestration-based saga
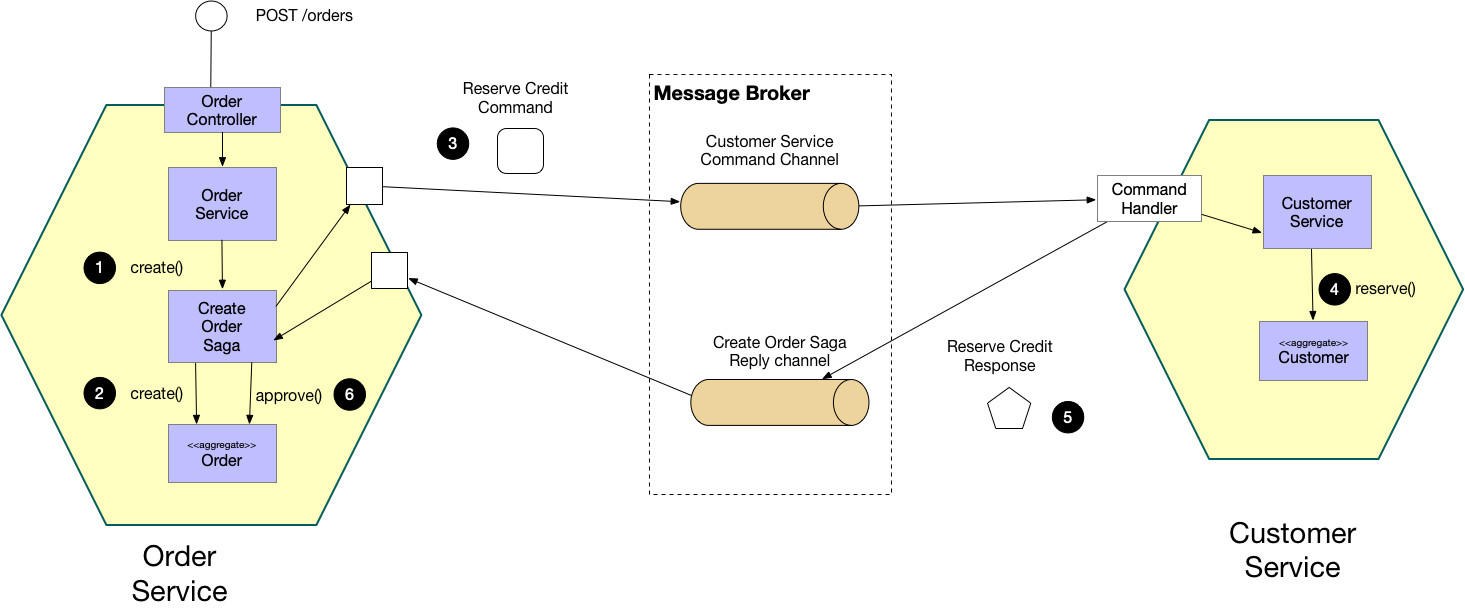
An e-commerce application that uses this approach would create an order using an orchestration-based saga that consists of the following steps:
- The
Order Servicereceives thePOST /ordersrequest and creates theCreate Ordersaga orchestrator - The saga orchestrator creates an
Orderin thePENDINGstate - It then sends a
Reserve Creditcommand to theCustomer Service - The
Customer Serviceattempts to reserve credit - It then sends back a reply message indicating the outcome
- The saga orchestrator either approves or rejects the
Order
Resulting context
This pattern has the following benefits:
- It enables an application to maintain data consistency across multiple services without using distributed transactions
This solution has the following drawbacks:
- The programming model is more complex. For example, a developer must design compensating transactions that explicitly undo changes made earlier in a saga.
There are also the following issues to address:
In order to be reliable, a service must atomically update its database and publish a message/event. It cannot use the traditional mechanism of a distributed transaction that spans the database and the message broker. Instead, it must use one of the patterns listed below.
A client that initiates the saga, which an asynchronous flow, using a synchronous request (e.g. HTTP
POST /orders) needs to be able to determine its outcome. There are several options, each with different trade-offs:- The service sends back a response once the saga completes, e.g. once it receives an
OrderApprovedorOrderRejectedevent. - The service sends back a response (e.g. containing the
orderID) after initiating the saga and the client periodically polls (e.g.GET /orders/{orderID}) to determine the outcome - The service sends back a response (e.g. containing the
orderID) after initiating the saga, and then sends an event (e.g. websocket, web hook, etc) to the client once the saga completes.
- The service sends back a response once the saga completes, e.g. once it receives an
Related patterns
- The Database per Service pattern creates the need for this pattern
- The following patterns are ways to atomically update state and publish messages/events:
- A choreography-based saga can publish events using Aggregates and Domain Events
Comments
Post a Comment